pxelinux 6.03 boot failure with Chelsio T520-LL-CR
This a collection of notes I have taken while debugging a regression of CERN PXE booting infrastructure, which followed the update to PXELINUX 6.03. This investigation brought me down the stack to the device firmware, reminding me of Eric Raymond’s “The Cathedral and the Bazaar” and the problem of closed hardware drivers. The devices I was working with were not at End of Life, however not having access to firmware code brought my turnaround time for finding a long term fix from 24 hours to days. In the widget frosting OSS model, Raymond advocates for an intermediate approach between open and closed source, where there is a closed source ROM and an open interface to the ROM. I was essentially in this configuration, working on top of Universal Network Device Interface (UNDI). Unfortunately, still not enough to enable me to effectively do my job.
Background and setup
At some point at the beginning of 2016, given the increasing necessity to support UEFI PXE boot, a decision was taken to upgrade the old PXELINUX 4 to PXELINUX 6.03. Everything went well, except that a relatively small subset of machines could not PXE boot anymore after the upgrade (in legacy mode, as they had always done in the past). We realized that this regression was confined to three flavors of machines, using three specific NICs: Chelsio T520-LL-CR, Mellanox ConnectX-2 and QLogic cLOM8214. The symptoms were not really pointing anywhere. The ROM of the NIC was correctly initializing the stack, going through the whole DHCP discover, offer, request, ACK workflow, and it was finally loading correctly pxelinux image from the server, which was then being given control. PXELINUX initial banner was displayed and after a long delay, a timeout message was appearing: “Failed to load ldlinux.c32”. And then a reboot. (Picture below shows pxelinux 6.04, but all these notes have been taken while working with 6.03).
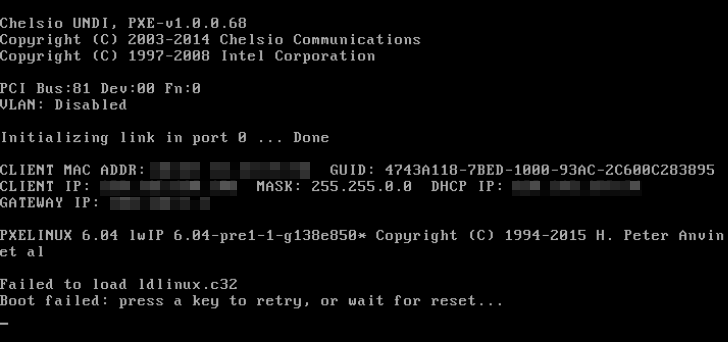
The components involved
The infrastructure for PXE boot involves several components: a NIC, with its PXE-compliant firmware, a DHCP server, a TFTP server, a PXE implementation that does the heavy lifting, that is, loading and booting the kernel and initrd, and the network in-between the clients/servers. At first, I was doubtful that any useful debugging could happen. The situation was the following:
- Limited control over the network infrastructure (different team responsible for that)
- No control over the firmware of the NIC (proprietary black box)
- Limited control over the DHCP server (different team responsible for that)
- Limited control over the TFTP server (different team responsible for that)
- All the freedom to modify/compile PXELINUX
- All the freedom to change kernel/initrd, but that was already at a far too advanced stage of the process
At a second thought, some of these hurdles could be overcome without too much effort.
A quick look at the network
The first approach I attempted was to dump network traffic, in case something obvious would turn up. I could not dump the traffic on the machine itself during PXE boot, and dumping at the other end of the communication was not a good idea either, so I had port mirroring configured towards a host over which I had complete control. It worked well, mixed up with non-relevant traffic I could see my client loading pxelinux image and then going radio silence. Here I made the first assumption, that unfortunately turned out to be wrong later on: after relinquishing control to pxelinux, there is no network activity whatsoever.
DHCP and TFTP servers
The next component that I needed was my own DHCP/TFTP infrastructure, so that I could bypass the production servers and point directly to my test instances where I could deploy a custom pxelinux. This also turned out doable. What was necessary was the following:
- Bringing up a DHCP/TFTP server
- Adding the DHCP server to a list of machines to which DHCP traffic would be relayed (you need a good reason to be in that list!)
- Disabling any kind of DHCP answer from the production servers for the host under test
- Configuring my own DHCP instance to provide an answer for the host under test, pointing to the test TFTP server and custom pxelinux.
Interaction with the machine
Another import point to address was the interaction with the machine under test. The system I used was part of a quad enclosure installed in a water cooled rack in the Data Centre. Clearly, you don’t want to stand there with your keyboard/monitor for long time, as the noise, heat, air exhausted by the systems, all contribute to make the experience very tiring. The obvious way to proceed was to use KVM over IP, in order to have complete control over the system, and to perform power management operations via IPMI.
Deploying the correct binary
pxelinux is part of syslinux project and comes in two different flavors:
pxelinux.0 and lpxelinux.0. During this experiment, I was compiling and
testing the 32bits legacy version of pxelinux and I was working on git commit 138e850f.
The first binary that I tried to deploy with my test environment was pxelinux.0.
That worked flawlessly, I could boot without any problem. With lpxelinux.0 instead, the
behavior was identical to the production version: “Failed to load ldlinux.c32”,
and reboot. My understanding of the difference between the two was limited, but
the idea is the following:
- lpxelinux.0 natively supports HTTP and FTP transfers by integrating a full-fledged TCP/IP stack, lwIP, therefore interacting with the NIC only to transmit/receive layer 2 frames.
- pxelinux relies instead on the firmware of the NIC to implement network communication, therefore having to provide only application level payload formatted as required by the PXE standard.
Debug messages
A good point where to start was where the error message itself was raised.
A quick grep pointed to ./core/elflink/load_env32.c, function load_env32.
writestr("\nFailed to load ");
writestr(LDLINUX);This function starts the ELF module subsystem, by first trying to load the dynamic linker, ldlinux.c32, which is normally deployed on the TFTP server. This is consistent with the network traffic trace: the first time ldlinux tries to access the network, for some reason it fails and eventually it times out.
Something that I needed was debug messages, enabling those already present and adding more, if needed.
writestr didn’t seem something I could use: it was printing directly to the video buffer,
but it didn’t support format strings. dprintf, however, seemed to be more suitable
for the job. But what does dprinf do? By default, it is defined as vdprintf, and
a quick look at the code revealed that I could not expect messages to come up on
the KVM. The code was in fact writing directly on the registers of the UART.
/* Initialize the serial port to 115200 n81 with FIFOs enabled */
outb(0x83, debug_base + LCR);
outb(0x01, debug_base + DLL);
outb(0x00, debug_base + DLM);
[...]It turns out that DEBUG_STDIO can be enabled to redefine dprintf
as printf, having debug messages written directly on the video buffer. In my case,
serial port was actually good enough, I could easily copy/paste, which would
have been more difficult with KVM. Clearly, it was not my intention to go
down in the servers room and plug any connector to the machine. Again, modern
BMCs can redirect traffic on serial port on the network via Serial Over Lan. So,
- SOL activated
ipmitool -H <BMC_HOSTNAME> -I lanplus -U <USERNAME> -P <PASSWORD> sol payload enable <LANCHANNEL> <USER_ID>
ipmitool -H <BMC_HOSTNAME> -I lanplus -U <USERNAME> -P <PASSWORD> sol activate- Debug messages enabled in core/Makefile adding a couple of CFLAGS:
-DDEBUG_PORT=0x3f8-DCORE_DEBUG=1(there might have been a better way to do this…)
CFLAGS += -D__SYSLINUX_CORE__ -D__FIRMWARE_$(FIRMWARE)__ \\
-I$(objdir) -DLDLINUX=\"$(LDLINUX)\"
-DDEBUG_PORT=0x3f8 -DCORE_DEBUG=1- Serial console redirection disabled in the BIOS, to avoid too much noise on the SOL
Deploy, reboot and finally some debug output on the screen.
inject: 0x579d0 bytes @ 0x00022a30, heap 1 (0x0018c2b8)
start = 510, len = 79ef0, type = 1start = 100000, len = 7d206000, type = 1will inject a block start:0x3a1000 size 0x7cf65000inject: 0x7cf65000 bytes @ 0x003a1000, heap 0 (0x0018c280)
start = 7d306000, len = 1beb000, type = 2start = 7eef1000, len = 116000, type = 2start = 7f007000, len = 228000, type = 2start = 7f22f000, len = e1000, type = 2start = 7f310000, len = 4f0000, type = 2start = 80000000, len = 10000000, type = 2start = fed1c000, len = 24000, type = 2start = ff000000, len = 1000000, type = 2
PXELINUX 6.04 lwIP 6.04-pre1-1-g138e850* Copyright (C) 1994-2015 H. Peter Anvin et al
!PXE entry point found (we hope) at 8EBD:00FA via plan A
UNDI code segment at 8EBD len 3E0F
UNDI data segment at 8468 len A550
UNDI: baseio 0000 int 11 MTU 1500 type 1 "DIX+802.3" flags 0x0
[...]Tracing the execution
Starting from load_env32, I tried to follow the control
path while keeping an eye open for something that could be the root cause of the
failure to load ldlinux.c32 from the network. After some flawless execution,
the following seemed to be the relevant stack trace.
start_ldlinux [./core/elflink/load_env32.c]
_start_ldlinux [./core/elflink/load_env32.c]
spawn_load [./com32/lib/sys/module/exec.c]
module_load [./com32/lib/sys/module/elf_module.c]
image_load [./com32/lib/sys/module/common.c]
findpath [./com32/lib/sys/module/common.c]
fopen [./com32/lib/fopen.c]
open [./com32/lib/sys/open.c]
opendev [./com32/lib/sys/opendev.c]
open_file [./core/fs/fs.c]The upper layer of pxelinux was trying to load ldlinux.c32 via a file-like API that was abstracting the fact that the file was sitting on a remote TFTP server. In fact, many data structures and functions are involved in file operations, nothing very much different then what one would find on a Linux OS and libc. It is actually interesting to dive a bit deeper.
File-like API
opendev is called with a pointer to the __file_dev structure which
defines the input operation hooks available (read/open/close)
const struct input_dev __file_dev = {
.dev_magic = __DEV_MAGIC,
.flags = __DEV_FILE | __DEV_INPUT,
.fileflags = O_RDONLY,
.read = __file_read,
.close = __file_close,
.open = NULL,
};
struct file_info {
const struct input_dev *iop; /* Input operations */
const struct output_dev *oop; /* Output operations */
[...]
struct {
struct com32_filedata fd;
size_t offset; /* Current file offset */
size_t nbytes; /* Number of bytes available in buffer */
char *datap; /* Current data pointer */
void *pvt; /* Private pointer for driver */
char buf[MAXBLOCK];
} i;
};The function opendev shown below looks for a file_info structure available
in the statically allocated array __file_info and sets the input operations
pointer, iop, to __file_dev . It then returns the corresponding fd
(the index within __file_info). From now on,
any attempt to read from a file associated with the file descriptor will go
through __file_dev.read function pointer, i.e. __file_read.
int opendev(const struct input_dev *idev,
const struct output_dev *odev, int flags)
{
[...]
for (fd = 0, fp = __file_info; fd < NFILES; fd++, fp++)
if (!fp->iop && !fp->oop)
break;
if (fd >= NFILES) {
errno = EMFILE;
return -1;
}
[...]
if (idev) {
if (idev->open && (e = idev->open(fp))) {
errno = e;
goto puke;
}
fp->iop = idev;
}
[...]
}What does __file_read do? Well, it calls the protected mode I/O API, in particular
pmapi_read_file, which relies on file->fs->fs_ops->getfssec (getfssec is the
function that actually does the reading). The structures
file and fs_ops are shown below.
struct file {
struct fs_info *fs;
uint32_t offset; /* for next read */
struct ino1de *inode; /* The file-specific information */
};
struct fs_ops {
/* in fact, we use fs_ops structure to find the right fs */
const char *fs_name;
enum fs_flags fs_flags;
int (*fs_init)(struct fs_info *);
void (*searchdir)(const char *, int, struct file *);
uint32_t (*getfssec)(struct file *, char *, int, bool *);
void (*close_file)(struct file *);
void (*mangle_name)(char *, const char *);
[...]
};The file structure is identified by a handle (which is again basically an index
within an array) returned by searchdir hook above. This handle is associated
to the corresponding com32_filedata within file_info in function open_file
in the excerpt below, which is called after opendev.
__export int open_file(const char *name, int flags, struct com32_filedata *filedata)
{
int rv;
struct file *file;
char mangled_name[FILENAME_MAX];
dprintf("open_file %s\n", name);
mangle_name(mangled_name, name);
rv = searchdir(mangled_name, flags);
if (rv < 0)
return rv;
file = handle_to_file(rv);
if (file->inode->mode != DT_REG) {
_close_file(file);
return -1;
}
filedata->size = file->inode->size;
filedata->blocklg2 = SECTOR_SHIFT(file->fs);
filedata->handle = rv;
return rv;
}From file-like API to network
searchdir, is where things start to become specific to the medium that is used to
retrieve the file, in this case the network.
int searchdir(const char *name, int flags)
{
static char root_name[] = "/";
struct file *file;
char *path, *inode_name, *next_inode_name;
struct inode *tmp, *inode = NULL;
int symlink_count = MAX_SYMLINK_CNT;
dprintf("searchdir: %s root: %p cwd: %p\n",
name, this_fs->root, this_fs->cwd);
if (!(file = alloc_file()))
goto err_no_close;
file->fs = this_fs;
/* if we have ->searchdir method, call it */
if (file->fs->fs_ops->searchdir) {
file->fs->fs_ops->searchdir(name, flags, file);
[...]
}A file structure is allocated and this_fs is set as the entry
point for doing file operations, which results in a call to getfssec function,
the one actually responsible for the I/O. I was therefore
expecting this_fs to point to a network API (we are still trying to load ldlinux.c32
via TFTP). So, what is this_fs? It’s initialized in fs_init, which is called indirectly by
pxelinux.asm with a pointer to the desired fs_ops.
;
; do fs initialize
;
mov eax,ROOT_FS_OPS
xor ebp,ebp
pm_call pm_fs_init
section .rodata
alignz 4
ROOT_FS_OPS:
extern pxe_fs_ops
dd pxe_fs_ops
dd 0Indeed fs_ops in this case is pxe_fs_ops, defined in core/fs/pxe/pxe.c
and initialized with the callbacks that implement file operations via
PXE (i.e. TFTP).
const struct fs_ops pxe_fs_ops = {
.fs_name = "pxe",
.fs_flags = FS_NODEV,
.fs_init = pxe_fs_init,
.searchdir = pxe_searchdir,
.chdir = pxe_chdir,
.realpath = pxe_realpath,
.getfssec = pxe_getfssec,
.close_file = pxe_close_file,
.mangle_name = pxe_mangle_name,
.chdir_start = pxe_chdir_start,
.open_config = pxe_open_config,
.readdir = pxe_readdir,
.fs_uuid = NULL,
};So, a call to searchdir was relinquishing control to pxe_searchdir.
static void pxe_searchdir(const char *filename, int flags, struct file *file)
{
int i = PXERetry;
do {
dprintf("PXE: file = %p, retries left = %d: ", file, i);
__pxe_searchdir(filename, flags, file);
dprintf("%s\n", file->inode ? "ok" : "failed");
} while (!file->inode && i--);
}At this point some more digging turned out to be necessary.
Network layer 4 via lwIP
pxe_searchdir [./core/fs/pxe/pxe.c]
__pxe_searchdir [./core/fs/pxe/pxe.c]
allocate_socket [./core/fs/pxe/pxe.c]allocate_socket returns without errors. __pxe_searchdir tries
then to locate a “URL scheme” suitable for opening the URL that points to the
TFTP server.
for (us = url_schemes; us->name; us++) {
if (!strcmp(us->name, url.scheme)) {
if ((flags & ~us->ok_flags & OK_FLAGS_MASK) == 0) {
dprintf("Opening with URL scheme, function %#.10x\n",us->open);
us->open(&url, flags, inode, &filename);
}
found_scheme = true;
break;
}
}Identifying the function pointed by the us->open hook is simply a matter of
obtaining its linear address, 0x0000108e14, and grepping in the symbols file.
cat ./bios/core/lpxelinux.map | grep -i 108e14
0x0000000000108e14 tftp_openThe control path proceeds as follows, without any error whatsoever.
tftp_open [core/fs/pxe/tftp.c.]
core_udp_open [core/fs/pxe/core.c]
netconn_new [core/lwip/src/api/api_lib.c]
core_udp_sendto [core/fs/pxe/core.c]
netconn_sendto [core/lwip/src/api/api_lib.c]
netconn_send [core/lwip/src/api/api_lib.c]
tcpip_apimsg [core/lwip/src/api/tcpip.c]
sys_mbox_post [core/lwip/src/arch/sys_arch.c]
mbox_post [core/thread/mbox.c]A remark must be made regarding core_udp_* functions.
There are three different implementations available:
-
In core/legacynet/core.c,
core_udp_*functions invoke directly the hooks exported by the PXE firmware (e.g.PXENV_UDP_WRITE). This code is compiled and linked when building pxelinux.0. -
In core/fs/pxe/core.c,
core_udp_*functions invoke the lwIP API to implement network communication. This code is compiled and linked when building lpxelinux.0. -
In efi/udp.c,
core_udp_*functions invoke the UEFI firmware to implement network communication. This code is compiled and linked when building pxelinux for EFI.
Since I was building lpxelinux.0 for BIOS, the second situation was the one of interest.
In the trace above, netconn_new and netconn_sendto were the first occurrences
of the transition to the lwIP stack. Plunging into lwIP meant that a new set
of debug messages was also needed. lwIP defines several macros for debugging that
can be set in core/lwip/src/include/lwipopts.h. First, I enabled debug messages
coming from the UDP layer.
#define LWIP_DEBUG
#define UDP_DEBUG LWIP_DBG_ON
#define API_LIB_DEBUG LWIP_DBG_ONEverything seemed to be working fine.
core_udp_sendto: 808EAD22 0045
netconn_send: sending 51 bytes
udp_send
udp_send: added header in given pbuf 0x0038fc86
udp_send: sending datagram of length 59
udp_send: UDP packet length 59
udp_send: UDP checksum 0x7be9
udp_send: ip_output_if (,,,,IP_PROTO_UDP,)netconn_send was returning successfully. From the trace above,
the maximum call depth was reached with mbox_post, which was also returning
successfully. The function was appending the outgoing message to a list and it
was increasing a semaphore to allow the main thread (tcpip_thread in
core/lwip/src/api/tcpip.c) to service outgoing data. At this point, the relevant
call trace initiated by the main thread was the following:
do_send [core/lwip/src/api/api_msg.c]
udp_sendto_chksum [core/lwip/src/core/udp.c]
udp_sendto_chksum [core/lwip/src/core/udp.c]
ip_route [core/lwip/src/core/ipv4/ip.c]
udp_sendto_if_chksum [core/lwip/src/core/udp.c]
ip_output_if [core/lwip/src/core/ipv4/ip.c]
ip_output_if_opt [core/lwip/src/core/ipv4/ip.c]ip_output_if_opt was calling netif->output(), again difficult to trace
without pointing directly to the virtual address, 0x112646 in this case.
0x00000000001120b6 etharp_output
.text 0x00000000001121a0 0x0 liblpxelinux.a(slipif.o)
.text 0x00000000001121a0 0xb03 liblpxelinux.a(undiif.o)
0x00000000001121a0 undiarp_tmr
0x00000000001121dc undiif_start
0x000000000011292f undiif_input
*fill* 0x0000000000112ca3 0x1 00According to the mapping above, the output hook was residing somewhere
between 0x1121dc and 0x11292f, most likely in core/lwip/src/netif/undiif.c, where
code which interfaces directly with the hardware is defined. From undiif.c:
/*
* This file is a skeleton for developing Ethernet network interface
* drivers for lwIP. Add code to the low_level functions and do a
* search-and-replace for the word "ethernetif" to replace it with
* something that better describes your network interface.
*/Layer 2 and below
Enabling debug messages at the UNDIIF layer allowed to go down to layer 2.
#define LWIP_DBG_LEVEL LWIP_DBG_LEVEL_ALL
#define UNDIIF_DEBUG LWIP_DBG_ONcore_udp_sendto: 808EAD22 0045
undi xmit thd 'tcpip_thread'
undi: d:ff:ff:ff:ff:ff:ff s:00:07:43:2e:f8:50 t: 806 x0
arp: s:00:07:43:2e:f8:50 128.142.160.103 00:00:00:00:00:00 128.142.173. 34 x0
netconn_sendto succeded!From this new trace, I could derive that undi_transmit was being called, but
the debug information that was showing the outcome of the ARP request was
clearly wrong. Of course, since I was not seeing any traffic on the network,
that didn’t really come as a surprise. The source address 00:07:43:2e:f8:50 was
the one of the Chelsio card, but the destination MAC was resolved as
00:00:00:00:00:00. To go a bit deeper, I enabled UNDIIF_ARP_DEBUG.
Called core_udp_sendto for lwip
core_udp_sendto: 808EAD22 0045
find_entry: found matching entry 0
etharp_request: sending ARP request.
etharp_raw: sending raw ARP packet.Everything seemed to be fine up to this point, but mixed up with the other messages I could see the following entries:
etharp_timer: expired pending entry 0.
etharp_timer: freeing entry 0, packet queue 0x00391094.The pending ARP resolution request was timing out and it was being popped out of the queue. This pattern was repeating until the eventual timeout from higher up in the stack. At this point I realized that one of my assumptions, that no data was being sent/received from the NIC, was wrong. When looking at the traffic dump, in order to filter out uninteresting network activity, I was querying by IP, basically ruling out all traffic at the data link layer, ARP requests included. After having had another look at the network dump, the situation was pretty clear.
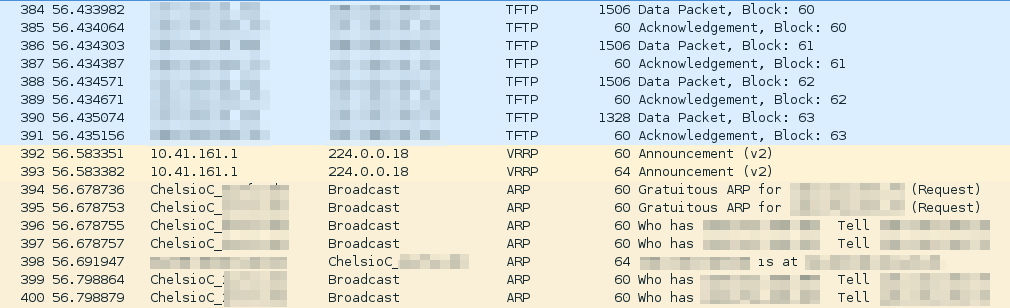
ARP requests were indeed being broadcasted on the local network! And the responses from the default gateway were there too! This changed completely the perspective of the problem: it seemed that the card was perfectly capable of transmitting traffic, but not to receive the responses.
Receiving data - Interrupt Service Routine
The interrupt service routine used by lpxelinux is defined in core/pxeisr.inc.
The ISR calls the PXENV_UNDI_ISR hook exported by the PXE capable firmware and
then checks one of the return flags, PXENV_UNDI_ISR_OUT_OURS, to make sure
that the interrupt “belongs to us”. From the PXE specification
When the Network Interface HW generates an interrupt the protocol driver’s
interrupt service routine (ISR) gets control and takes care of the interrupt
processing at the PIC level. The ISR then calls the UNDI using the
PXENV_UNDI_ISR API with the value PXENV_UNDI_ISR_IN_START for the FuncFlag
parameter. At this time UNDI must disable the interrupts at the Network Interface
level and read any status values required to further process the interrupt. UNDI
must return as quickly as possible with one of the two values, PXENV_UNDI_ISR_OUT_OURS
or PXENV_UNDI_ISR_OUT_NOT_OURS, for the parameter FuncFlag depending on whether
the interrupt was generated by this particular Network Interface or not.This flag tells pxelinux whether the interrupt was generated by the network card
from which the system is PXE booting or not. The ISR is installed
at the IRQ specified by the UNDI firmware itself, in pxe_start_isr,
int irq = pxe_undi_info.IntNumber;
if (irq == 2)
irq = 9; /* IRQ 2 is really IRQ 9 */
else if (irq > 15)
irq = 0; /* Invalid IRQ */
pxe_irq_vector = irq;
if (irq) {
if (!install_irq_vector(irq, pxe_isr, &pxe_irq_chain))
irq = 0; /* Install failed or stuck interrupt */
}On this system, the ISR is installed at IRQ 11. In real mode with a master-slave PIC system, IRQ 11 belongs to the slave PIC, which translates to the interrupt vector 0x70 + (IRQ - 0x8), namely 0x70 + 0x03, 0x73 as shown in the debug messages below.
UNDI: IRQ 11(0x73): 7e6c:509e -> 0000:7e40
pxe_start_isr: forcing pxe_need_pollThe meaning of the second message will become clear very soon.
The most important routines which are responsible for setting up interrupts are
pxe_init_isr and pxe_start_isr, which are both called by pxe_fs_init, although
at different call depths as shown in the trace below.
pxe_fs_init [core/fs/pxe/pxe.c]
pxe_init_isr [core/fs/pxe/isr.c]
network_init [core/fs/pxe/pxe.c]
net_core_init [core/fs/pxe/pxe.c]
undiif_start [core/lwip/src/netif/undiif.c]
netifapi_netif_add [core/lwip/src/api/netifapi.c]
netif_add [core/lwip/src/core/netif.c]
init (undiif_init) [core/lwip/src/netif/undiif.c]
low_level_init [core/lwip/src/netif/undiif.c]
pxe_start_isr [core/fs/pxe/isr.c]pxe_init_isr starts the pxe_receive_thread
thread, which basically loops indefinitely, first suspending on the
pxe_receive_thread_sem semaphore and, when triggered, calling pxe_process_irq.
pxe_start_isr starts the pxe_poll_thread and detects whether the hardware correctly
supports interrupts or polling is to be preferred. In the second case,
pxe_poll_thread becomes responsible for handling interrupts. As shown in the debug
trace above, pxe_start_isr detects that polling is to be preferred due to
the PXE_UNDI_IFACE_FLAG_IRQ flag returned directly by the UNDI firmware. The code
of the polling thread is shown below.
static void pxe_poll_thread(void *dummy)
{
(void)dummy;
/* Block indefinitely unless activated */
sem_down(&pxe_poll_thread_sem, 0);
for (;;) {
cli();
if (pxe_receive_thread_sem.count < 0 && pxe_isr_poll()) {
sem_up(&pxe_receive_thread_sem);
}
else
__schedule();
sti();
cpu_relax();
}
}pxe_poll_thread_sem is incremented by a callback function triggered
at regular intervals. The thread checks the status of the receive thread semaphore
and the return code of pxe_isr_poll, and, if necessary, ups pxe_receive_thread_sem
to trigger the receive thread.
static void pxe_receive_thread(void *dummy)
{
(void)dummy;
for (;;) {
sem_down(&pxe_receive_thread_sem, 0);
pxe_process_irq();
}
}I tried first to understand whether pxe_process_irq was ever called. It tuned out,
it was not and my attention was caught by pxe_isr_poll.
static bool pxe_isr_poll(void)
{
static __lowmem t_PXENV_UNDI_ISR isr;
isr.FuncFlag = PXENV_UNDI_ISR_IN_START;
unsigned int ret = pxe_call(PXENV_UNDI_ISR, &isr);
return isr.FuncFlag == PXENV_UNDI_ISR_OUT_OURS;
}This function performs in polling mode the same checks as pxe_isr in core/pxeisr.inc,
In particular, it returns true if PXENV_UNDI_ISR_OUT_OURS is set.
Going back to PXENV_UNDI_ISR_OUT_OURS once again:
If the value returned in FuncFlag is PXENV_UNDI_ISR_OUT_NOT_OURS, then the
interrupt was not generated by our NIC, and interrupt processing is complete.
If the value returned in FuncFlag is PXENV_UNDI_ISR_OUT_OURS, the protocol driver
must start a handler thread and send an end-of-interrupt (EOI) command to the PIC.
Interrupt processing is now complete.After playing a bit with pxe_isr_poll, it turned out PXENV_UNDI_ISR_OUT_OURS was
never set, keeping pxe_receive_thread indefinitely suspended on the semaphore.
The first naive attempt was to replace the condition in the return statement
return isr.FuncFlag == PXENV_UNDI_ISR_OUT_OURS;with
return 1;Reboot and… it worked! Loading initramfs, kernel and booting! Apparently, the flag
returned by the UNDI firmware was always cleared, preventing lpxelinux
from properly handling incoming data. The firmware was probably ignoring altogether
that flag, which worked as long as pxelinux was not involved in the interrupt handling.
Unfortunately, this marked the end of the investigation: I could not
fix the issue myself as I did not have any control over the sources of the firmware of the NIC.
Considering PXENV_UNDI_ISR_OUT_OURS as always set was not an
option either, as it could break the execution on hardware with multiple NICs sharing the
same IRQ (or in the best case, it would result in the invocation of the routine for servicing the
interrupt for no reason).
Updates
- QLogic cLOM8214 turned out to be affected by the same issue, and can boot
just fine if
PXENV_UNDI_ISR_OUT_OURSis always set. However, this NIC has been discontinued and no fixes will be provided. Speaking of widget frosting… - Chelsio has provided a firmware fix which allows to boot correctly with lpxelinux 6.03
- Background and setup
- The components involved
- A quick look at the network
- DHCP and TFTP servers
- Interaction with the machine
- Deploying the correct binary
- Debug messages
- Tracing the execution
- File-like API
- From file-like API to network
- Network layer 4 via lwIP
- Layer 2 and below
- Receiving data - Interrupt Service Routine
- Updates