Maximizing throughput of iSCSI storage setup
I have run some tests on my iSCSI backend, with the intent of planning several upgrades, including routing ethernet cables to the studio, as I am currently on a wireless network. This exercise forced me to try to produce a model that describes the throughput of iSCSI requests. What I eventually got seems to work and it enabled me to make data-driven performance projections with different configurations that I then verified experimentally.
While the model is precise enough to be useful in the configurations I have tested, I cannot guaranteed it will be accurate if those conditions change. Unfortunately, my understanding of iSCSI is still too shallow. I intend to review the content of this post in the future. Still, for now, I could predict throughput on multiple setups (e.g. Gigabit ethernet instead of wireless, SSD instead of spinning disk), with an acceptable degree of accuracy, so I consider this a good start.
NAS setup
The NAS which exports the iSCSI volume runs on a Helios4 board (the legacy 32-bit one, not the updated Helios 64-bit SoC). The chassis has been 3d printed, though it is still missing the front, back, and rear panels (I only had a 3d printer available for a limited amount of time and haven’t decided yet if I would make good use of my own one). Initially, the NAS was fitted with Hitachi Ultrastar (7.2k) SATA spinning disks, but I have also added a Samsung EVO SSD to get latency numbers on Solid State Drive.
The goal of the performance analysis was mainly to answer the following questions:
- Why am I getting 30 MiB/s of Direct I/O sequential write throughput if network and storage,
even with spinning disks, can run much faster? In particular, network transfers can reach 75 MiB/s (
iperf3), and storage can handle even higher throughput sequential writes. - What would be the gain if I routed Gigabit ethernet to the clients?
- What would be the gain if I replaced the current spinning disk setup with SSDs?
Network configuration
By default, the NAS is on a wireless 802.11ac network. Throughput is
600 Mbit/s, measured with iperf3. In terms of latency, to which we will see iSCSI
is very much sensitive, I initially estimated 4ms of RTT by just looking at the
delays recorded by ping. However, after collecting more samples and looking more closely at the results,
I realized that when ping uses 1s intervals between packets, we get a bimodal latency distribution as in the picture below.
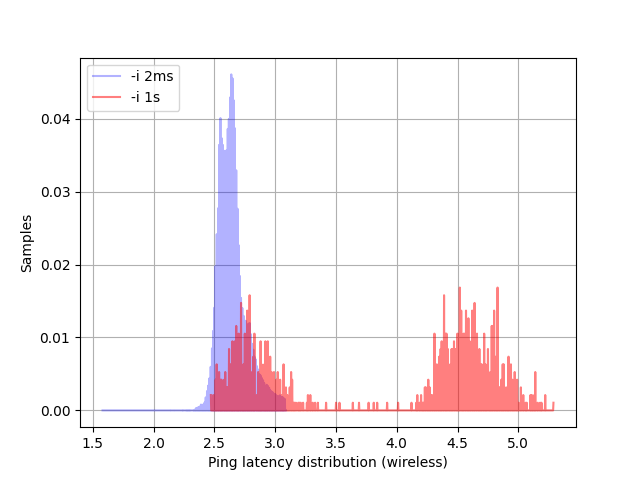
4ms is the center of the higher distribution. Using 4ms as RTT latency in the performance model underestimates the real throughput.
The bimodal distribution does not appear if the ping interval is 2ms, which is much closer to the
interval between iSCSI packets exchanged during I/O. I am not sure I can fully explain why we see a bimodal distribution
and I will need to run more tests. My current thought is that the standard deviation is too significant to be attributed to anything else but the network.
In the model that follows, I have used the average of the 2ms interval distribution, which not surprisingly yields much more precise results.
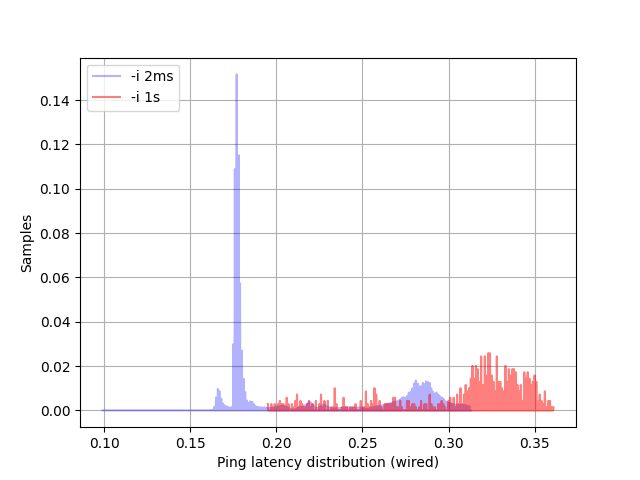
I have also collected throughput and latency measurements on wired Gigabit Ethernet so that I could input these values to the
model and make predictions on the overall iSCSI workload. The throughput measured with iperf is 930 Mbit/s, while latency results are
shown in the graph below. The distribution shows clearer multi-modes
in the 2ms interval results. However, given a more reasonable Coefficient of variation (standard deviation over the mean) in this
distribution compared to the 802.11ac network, I have just used the average over all the 2ms samples.
Below I have collected a summary of the latency statistics with different intervals on wired and wireless networks
(i.e. ping -i <INTERVAL>). The numbers are conveniently calculated on the command line with
datamash mean 1 perc:50 1 perc:99 1 max 1 sstdev 1. I have collected 15 minutes worth of samples at different packet
intervals, so the overall number of samples collected is different. It is good enough, for the scope of the problem
I am dealing with.
| mean (ms) | p50 (ms) | p99 (ms) | max (ms) | sstdev | Coff. var | |
|---|---|---|---|---|---|---|
| wired 1s | 0.31 | 0.32 | 0.54 | 0.90 | 0.06 | 19.5% |
| wireless 1s | 5.50 | 4.42 | 34.61 | 299 | 12.95 | 234.5% |
| wired 2ms | 0.22 | 0.18 | 0.35 | 0.77 | 0.05 | 22.7% |
| wireless 2ms | 2.95 | 2.64 | 7.63 | 133 | 3.32 | 112.5% |
fio benchmarks
The basic configuration for fio benchmarks is the following:
direct=1-
sync=0(default) numjobs=1size=5G-
rw=write(sequential workload)
I have used fio-3.30 for block devices tests and built from sources fio-3.36-17 for libiscsi tests.
The default configuration of the “parameters” section of the iSCSI backend is the following:
| Parameter | Value |
|---|---|
| AuthMethod | CHAP,None |
| DataDigest | CRC32C,None |
| DataPDUInOrder | Yes |
| DataSequenceInOrder | Yes |
| DefaultTime2Retain | 20 |
| DefaultTime2Wait | 2 |
| ErrorRecoveryLevel | 0 |
| FirstBurstLength | 65536 |
| HeaderDigest | CRC32C,None |
| IFMarkInt | Reject |
| IFMarker | No |
| ImmediateData | Yes |
| InitialR2T | No |
| MaxBurstLength | 262144 |
| MaxConnections | 1 |
| MaxOutstandingR2T | 1 |
| MaxRecvDataSegmentLength | 8192 |
| MaxXmitDataSegmentLength | 262144 |
| OFMarkInt | Reject |
| OFMarker | No |
| TargetAlias | LIO Target |
fio benchmarks have been executed in three different configurations:
- Locally, with
sgengine - Remotely, directly on iSCSI exported block device (e.g.
file=/dev/<BLOCK_DEVICE>), with default I/O engine - Remotely, with
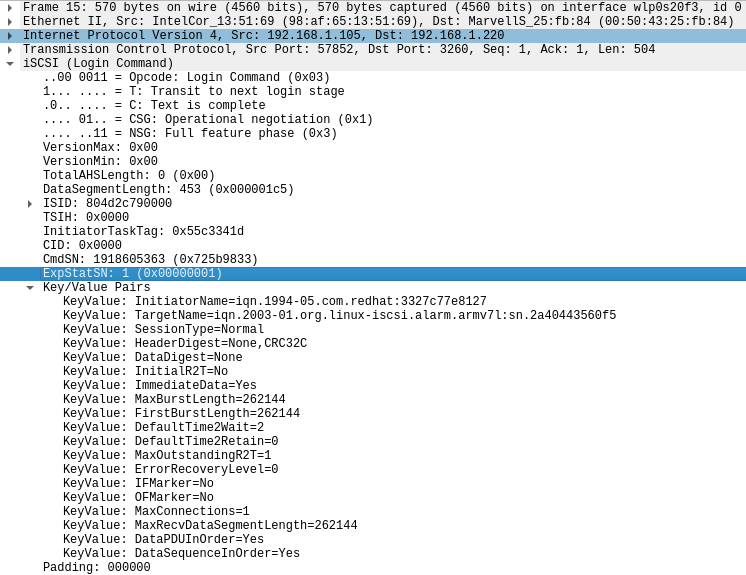
libiscsiengine. It must be noted however thatlibiscsiseems to be negotiating some session parameters without honoring target configuration on the backend, so for example even if the backend is configured to useMaxOutstandingR2T=16, I still seeMaxOutstandingR2T=1being negotiated. The set of default parameters used bylibiscsiin my tests were as per the screenshot below:
and the full fio configuration file is reported below.
fio configuration file for libiscsi tests
[sequential-write]
rw=write
size=5G
direct=1
numjobs=1
group_reporting
name=sequential-write-direct
bs=2M
sync=0
runtime=60
ioengine=libiscsi
filename=iscsi\://192.168.1.220\:3260/iqn.2003-01.org.linux-iscsi.alarm.armv7l\:sn.2a40443560f5/0
All configurations above have been tests with with O_DIRECT and without O_SYNC.
Local benchmarks
The following table summarizes the results of local benchmarks, i.e. using sg engine directly on the drive.
fio sg HDD |
fio sg SSD |
|
|---|---|---|
| (MiB/s, IOPS) | (MiB/s, IOPS) | |
| 64k | 128/2055 | 329/5268 |
| 128k | 135/1082 | 348/2786 |
| 256k | 137/546 | 359/1434 |
| 512k | 137/273 | 363/726 |
| 1M | 136/136 | 360/360 |
| 2M | 136/67 | 354/176 |
Wireless network benchmarks
The following table shows the results of remote (block device and libiscsi) benchmarks on wireless network:
fio libiscsi HDD |
fio iSCSI block dev HDD | fio iSCSI block dev SSD | |
|---|---|---|---|
| (MiB/s, IOPS, CPU util) | (MiB/s, IOPS) | (MiB/s, IOPS) | |
| 64k | 18.3/292/7% | 15.5/237 | 13.7/219 |
| 128k | 17/138/7% | 15.1/121 | 14.8/118 |
| 256k | 24.4/97/8% | 22.6/90 | 21.8/87 |
| 512k | 28.7/57/10% | 27.5/54 | 29.3/58 |
| 1M | 30.8/30/12% | 30.1/30 | 33.4/33 |
| 2M | 33.1/16/14% | 31.0/15 | 34.5/17 |
As mentioned earlier, fio benchmarks are executed with direct=1 (O_DIRECT) and sync=0 (no O_SYNC), so we are bypassing
caches between kernel and userspace and we are writing I/O data directly to DMA buffers (I looked a bit more closely into DMA
mechanisms in the past while debugging network I/O on ARM64 systems)
. O_DIRECT will not give any guarantee that data is stored on the device (for that, we would need O_SYNC).
Writing to DMA buffers implies that device throughput will have an impact on performance, as DMA regions are normally
tracked in hardware ring buffers that are consumed at the device’s speed. We see from iSCSI block device benchmarks above that
HDD and SSD block device throughputs with O_DIRECT from the client perspective differ by 10% at 2M. This might sound
counterintuitive because we are doing only 15 IOPS end to end, while the spinning disk at 2M
can handle 67 raw IOPS and CPU is at 14% utilization, which if projected linearly, should result in the ability to
handle ~112 IOPS at 100% utilization. However, despite being far from those 67 raw IOPS, we still see device I/O overhead
for every operation, deriving from DMA buffer management with the drive. So, we need to consider some latency as synchronous to the
request. It probably is not as high as the request latency at max IOPS, where other dynamics such as ring buffer saturation
are at play, but considering those numbers anyway will make us underestimate expected throughput, which is fine.
On the network side, iperf3 benchmarks show sustained 75 MiB/s (600 Mbit/s) (that would correspond to 38 IOPS at 2M).
This however is the best-case scenario,
with a communication consisting of a raw stream of bytes. iSCSI communication involves much more
back and forth between server and client. In particular, a look at network traffic gives an idea of what messages are
being exchanged:
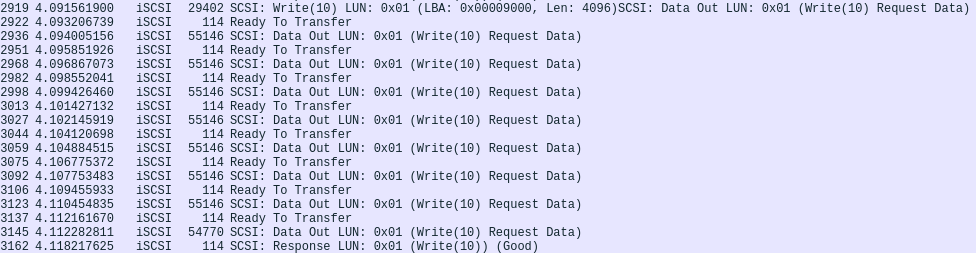
The target sends a R2T (Ready to Transfer) packet for every Data PDU (256 KiB) necessary to make up the block size, 2M in this case. Every single R2T introduces a full one-way latency cost, and so does the Data PDU answer. So, considering 2M blocks, a model describing this communication could be the following:
| Request latency | ||
| – | ————————– | d |
| 1 | one-way latency for immediate data (64K) | |
| 2 | transmission duration of immediate data | |
| 3 | one-way latency for R2T | |
| 4 | one-way latency for data PDU | |
| 5 | transmission duration for 256K data | |
| 6 | goto 3. seven times | |
| 7 | one-way latency for R2T | |
| 8 | one-way latency for last fractional data PDU | |
| 9 | transmission duration for 256K-64K data | |
| 10 | one-way latency for “Command completed at target” message |
Mapping the benchmark results above to this model would result in the following:
| Request latency | ||
|---|---|---|
| 1 | 1.5ms | one-way latency for immediate data (64K) |
| 2 | 0.87ms | transmission duration of immediate data |
| 3 | 1.5ms | one-way latency for R2T |
| 4 | 1.5ms | one-way latency for data PDU |
| 5 | 0.87ms*256K/64K | transmission duration for 256K data |
| 6 | goto 3. seven times | |
| 7 | 1.5ms | one-way latency for R2T |
| 8 | 1.5ms | one-way latency for last fractional data PDU |
| 9 | 0.87ms*(256K-64K)/64K | transmission duration for 256K-64K data |
| 10 | 1.5ms | one-way latency for “Command completed at target” message |
This however takes into account only network I/O. In terms of CPU cycles of the iscsi_trx kernel thread,
I am unclear on what exactly is being done in that time (e.g. CRC calculation, but some quick tests indicate that
there is far more than that) and I’ll
have again to take a closer look into LIO source code. Assuming that time is synchronous to the request.
To decide how much time to attribute to every 2M operation, we need first to consider that the latency cost coming from the synchronous request handling by the drive needs to be aligned with the “real” IO size. In fact, despite iSCSI working with 2M blocks, the drive sees 1M requests:
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
mmcblk0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 30.00 30720.00 0.00 0.00 6.70 1024.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.20 18.00
I have tested that for all block sizes, the drive is serving operations of half of the block size (to
be clarified why this is the case). This is important as the synchronous latency we want to add to the model
above should reflect 1M I/O, assuming that a 2M request can be split in half on the fly and the initial 1M
latency can be shadowed by the second half of the network block transfer, at least partially.
To transfer 1M, we would need 0.87 ms (64 KiB transfer) * 16 = 13.9 ms. A single 1M IO request on the HDD would take
1000ms /136 IOPS = 7.3 ms, so this seems to be reasonable.
I have decided to attribute to the request all CPU cycles as synchronous latency, which puts the results in the worst-case scenario. The reason is that according to the reasoning above, the faster the network becomes, the higher would be the impact of CPU processing as the shadowing effect would become less relevant. I have used the 1M request latency as a reference (with 12% CPU utilization at 30 IOPS), which yields 8ms per 2MB request.
If we put everything together:
1.5+0.87+(1.5+1.5+256/64*0.87)*7+(1.5+((256-64)/64)*0.87+1.5)+1.5+7.3+8 = 70.14 ms (14.3 IOPS, 28.5 MiB/s)
We see 31.0 MiB/s on the block device benchmark so, we get a projection that diverges by ~8% from the real value.
Reducing R2T latency
I am not the first one outlining the impact of R2T of iSCSI throughput, especially on high latency networks.
Documentation of Linux SCST SCSI subsystem was a first good pointer for me.
Ready to Transfer packets are sent out according to MaxOutstandingR2T configuration parameter. This value
determines how many R2T can be sent without having received back the corresponding Data PDU. By default,
it is set to 1, which means that after a R2T is sent to the initiator, we have to wait for the Data PDU
before the next R2T. MaxOutstandingR2T can be tweaked to minimize the latency cost coming from R2Ts.
Considering a 2M block transfer with 256 KiB MaxBurstLength, we’ll need 8 R2T to transfer the whole block,
so setting a value of at least 8 for MaxOutstandingR2T means that all R2Ts necessary for the block will
go out at once as in the following network dump:
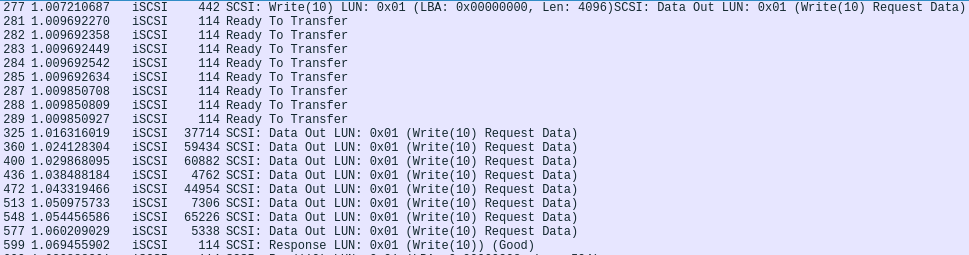
This significantly reduces the impact of latency over the communication and an updated mathematical model could be the following:
| Request latency | |
|---|---|
| 1 | one-way latency for immediate data (64K) |
| 2 | transmission duration of immediate data |
| 3 | one-way latency for 8 R2T (transfer time is negligible) |
| 4 | one-way latency for data PDU |
| 5 | transfer time for 2M-64K |
| 6 | one-way latency for “Command completed at target” message |
Considering again the 2M transfer on wireless network as above, we get:
1.5+0.87+1.5+1.5+(1984/64)*0.87+1.5+7.3+8 = 49.14 ms (20.4 IOPS, 40.8 MiB/s)
The actual throughput in this configuration is 42 MiB/s, so the projection diverges by ~3%.
Projections
Using the models above for R2T=1 and R2T=16, I tried to project throughput in several configurations, which I then verified experimentally.
Below are the results:
| R2T | I/O lat (1M) | CPU lat (1M*2) | Net lat | Net 64 KiB (MiB/s) | Ops (ms) | IOPS | Est. thr (MiB/s) | Actual thr (MiB/s) | Error (%) | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 7.3 | 8 | 1.5 | 0.87 | 70.14 | 14.26 | 28.51 | 31 | 8.02 | |
| 7.3 | 8 | 0.11 | 0.5 | 34.67 | 28.84 | 57.69 | 62 | 6.96 | ||
| 2.7 | 8 | 0.11 | 0.5 | 30.07 | 33.26 | 66.51 | 72 | 7.62 | ||
| 16 | 7.3 | 8 | 1.5 | 0.87 | 49.14 | 20.35 | 40.70 | 42 | 3.1 | |
| 7.3 | 8 | 0.11 | 0.5 | 31.74 | 31.56 | 63.01 | 70 | 9.98 | ||
| 2.7 | 8 | 0.11 | 0.5 | 27.14 | 36.85 | 73.69 | 82 | 10.13 |
The error for R2T=1 is confined between 7% and 8%. For R2T=16 the error is stable at 10% except in the slowest scenario, i.e. spinning disk over wireless network,
where it drops to 3%. I suspect this outlier might be related to the variability of wireless network latency. In particular, in R2T=16 mode, the number of messages exchanged
between client and server is lower compared to R2T=1 and the network latency estimate based on 2ms intervals might not be accurate. With 20 IOPS and 4 one-way latency contributions
for each operation, we would have 12ms intervals. Truth be told, I have run a quick ping test and I haven’t seen a significant difference with the 2ms results. I haven’t investigated
further as these results are still good enough to inform the architectural decisions summarized in the last section.
Conclusions
Reducing network latency is a must to obtain decent performance over iSCSI, and so is modifying R2T configuration to allow for Ready To Transfer bursts.
With O_DIRECT, the benefits from moving from slow spinning disk to SSD are limited to +17% speedup on wired network. This is not negligible, by
it is dwarfed by local speedup, which reaches 160%. I’d get close to line speed only by moving to wired network and eliminating deviced
latency and CPU latency. The following are the conclusions I have come to so far with these experiments:
- Moving to wired Gigabit ethernet is a must, regardless of
O_DIRECT - Moving to SSD has a modest impact on performance in
O_DIRECT. I haven’t tested withoutO_DIRECT, but at least on the receiving end, an additional caching layer would result in significant benefits by making I/O latency and CPU latency asynchronous.